3DEditVerse¶
3DEditVerse: A Dataset and Dual-Guidance Editing Model for 3D Objects (2025.10)
3DEditVerse 是 3D 编辑领域中少见的同时贡献数据集和专用编辑模型的工作。它的核心判断是:training-free 方法虽然灵活,但上限有限;要提升 3D 编辑质量,必须有大规模高质量配对数据 + 专门设计的编辑架构。最终结果是:无需掩码,3D 指标比带掩码的 VoxHammer 提升了 13%。
数据集:3DEditVerse¶
3DEditVerse 数据集包含 116,309 对训练样本 和 1,500 对测试样本,覆盖几何编辑和外观编辑两种类型。数据构建通过两条独立的 pipeline 完成。
这篇工作的一个强点在于,它没有只追求数据量,而是明确把数据集设计成四个目标同时成立:
- 编辑区域是局部的
- 训练规模足够大
- 编辑前后保持跨视角一致
- 编辑结果和未编辑区域在语义上协调
论文也把它和已有数据做了直接对比:相比 3D-Alpaca-Editing、CMD、Edit3D-Bench,3DEditVerse 是少数同时满足 localized edit region + scalability + consistency + harmony 的数据集。
Pipeline 1:几何编辑对(Geometry)¶
几何编辑对的构建思路是利用角色-动画的组合来自然生成"同一物体、不同姿态"的配对:
- 从 Objaverse 中筛选角色-动画组合
- 通过 DINOv2 特征做去重,保留 4,998 个独特姿态
- 108 个角色 × 500 个姿态 = 54,000 对几何编辑训练样本
这种方式的优势在于:配对数据天然对齐,几何变化真实且多样,不需要人工标注。
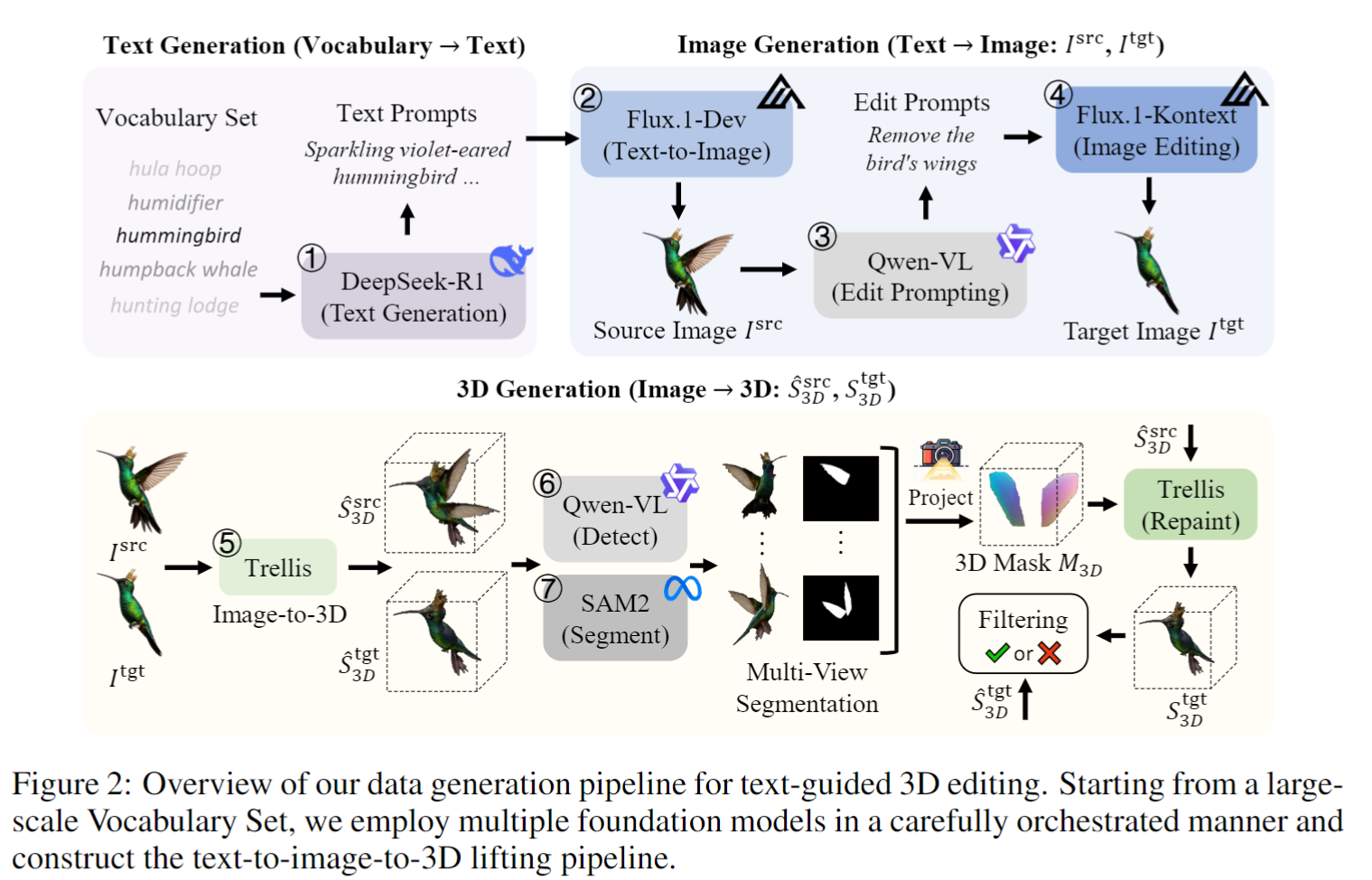
Pipeline 2:外观编辑对(Appearance)¶
外观编辑对的构建是一个多阶段自动化流水线,涉及多个大模型协作:
| 阶段 | 操作 | 使用的模型/工具 |
|---|---|---|
| 1 | 生成编辑指令 | DeepSeek-R1 |
| 2 | 2D 图像生成 | Flux.1-Dev |
| 3 | 视觉质量检查 | Qwen-VL |
| 4 | 局部图像编辑 | Flux.1-Kontext |
| 5 | 2D → 3D 提升 | Trellis |
| 6 | 开放集目标检测 | Qwen-VL |
| 7 | 多视图 3D 掩码生成 | SAM2 |
| 8 | 局部 3D 编辑 | Trellis + Repaint |
| 9 | 一致性过滤 | DINOv2 |
其中多视图 3D 掩码投影是关键步骤:在 \(N=70\) 个视角上进行投票,通过阈值 \(\tau\) 确定哪些 3D 区域属于编辑目标。这确保了 2D 分割结果能准确映射到 3D 空间。
最终通过 DINOv2 一致性过滤,淘汰编辑前后变化过大或过小的低质量样本。
模型:3DEditFormer¶
3DEditFormer 构建在 TRELLIS 骨干之上,主要设计是多阶段特征提取 + 双引导注意力 + 时间自适应门控。重要的一点:不需要掩码——模型端到端学习"在哪里编辑、编辑什么"。
多阶段特征提取(Multi-Stage Feature Extraction)¶
3DEditFormer 从 TRELLIS 的去噪过程中提取两种互补特征:
| 特征 | 提取时刻 | 条件 | 编码的信息 |
|---|---|---|---|
| \(f_{3D}^{(1)}\)(细粒度结构特征) | 晚期时步 \(t_1 \approx 0\) | 空图像条件 | 原始 3D 物体的几何细节 → 用于保留 |
| \(f_{3D}^{(2)}\)(语义转换特征) | 早期时步 \(t_2 \approx 1\) | 目标编辑图像 | 结构应该如何变化 → 用于编辑 |
这个设计背后的直觉是:
- 在去噪接近完成时(\(t_1 \approx 0\)),模型已经恢复了大部分几何细节,此时提取的特征最能代表原始物体的精细结构
- 在去噪刚开始时(\(t_2 \approx 1\)),模型刚接收到目标图像条件,此时的特征最能反映"从原始到目标的语义变化方向"
这一设计的价值,在于它把 3D 编辑中的两个目标拆开处理:
- 什么地方要尽量保持不变
- 什么地方应该朝目标图像发生变化
双引导注意力模块(Dual-Guidance Attention Block)¶
两种特征通过并行交叉注意力融入生成过程:
其中:
- \(h_1\):自注意力输出(冻结,来自原始 TRELLIS)
- \(h_2\):与结构特征 \(f_{3D}^{(1)}\) 的交叉注意力 → 负责保留未编辑区域
- \(h_3\):与语义特征 \(f_{3D}^{(2)}\) 的交叉注意力 → 负责驱动编辑变化
- \(g_1, g_2\):时间自适应门控系数
时间自适应门控(Time-Adaptive Gating)¶
门控系数会随去噪时步动态变化:
这意味着模型可以在去噪的不同阶段动态调整保留与编辑的平衡:
- 去噪早期:可能更偏向语义引导,确定大致的编辑方向
- 去噪后期:可能更偏向结构保留,精修细节
这种设计有效地解决了 3D 编辑中的主要矛盾——编辑强度 vs 未编辑区域保持。
从论文表述看,这也是 3DEditFormer 和普通 cross-attention 微调的主要差别:它会显式地区分“保留信号”和“变化信号”,不只是简单把 source feature 喂进去。
训练策略¶
训练采用了高效的微调方案:
| 项目 | 设置 |
|---|---|
| TRELLIS 骨干 | 冻结 |
| 可训练参数 | 252M(交叉注意力、FFN、门控 MLP) |
| 训练迭代 | 40k |
| Batch size | 16 |
| 优化器 | AdamW |
| 训练目标 | Conditional Flow Matching |
冻结骨干 + 只训练新增模块,既保留了 TRELLIS 强大的 3D 生成先验,又让模型高效学会编辑能力。
从工程角度看,这个设置也比较现实:它没有要求从头训练一个全新的 3D foundation model,而是把编辑能力作为 TRELLIS 上的一层专门适配。
实验结果¶
核心对比¶
3DEditVerse 在 3D 编辑指标上优于 VoxHammer:
无需掩码的 3DEditFormer,比需要掩码的 VoxHammer 在 3D 指标上提升了 13%。
这是一个值得注意的结果——VoxHammer 需要用户提供精确的 3D 掩码来指定编辑区域,而 3DEditFormer 完全不需要任何掩码输入。
更具体地看,在全测试集上,3DEditFormer 相比 EditP23 的结果是:
CD: 46.19 -> 13.84NC: 0.689 -> 0.830F1: 32.33 -> 64.30PSNR: 18.32 -> 24.40LPIPS: 0.158 -> 0.068DINO-I: 0.785 -> 0.963
这些数值说明它不仅编辑更准,而且未编辑区域的几何和外观保持也更稳定。
VoxHammer 的掩码敏感性¶
实验还揭示了 VoxHammer 的一个关键弱点:
- 当掩码精度下降时(扩展 9%、18%),VoxHammer 性能明显退化
- 这说明 training-free 方法对输入条件的质量非常敏感
论文实际上还继续测到了 27% 的 mask 扩张,性能继续下滑。这一点很关键,因为它说明 VoxHammer 的问题不仅在于“需要 mask”,更在于对 mask 误差很敏感。
相比之下,3DEditFormer 由于端到端学习了编辑区域定位,完全规避了这个问题。
消融实验¶
每个组件都有独立贡献:
| 组件 | 作用 |
|---|---|
| 细粒度结构特征 \(f_{3D}^{(1)}\) | 提升未编辑区域的保持质量 |
| 语义转换特征 \(f_{3D}^{(2)}\) | 提升编辑区域的变化准确性 |
| 时间自适应门控 | 动态平衡两者,整体提升一致性 |
移除任一组件都会导致性能下降,验证了双引导 + 自适应门控设计的必要性。
论文表中的结果也比较一致:
- baseline:
CD 16.230,F1 60.183 - 加结构特征后:
CD 14.586,F1 63.701 - 再加语义特征:
CD 14.084,F1 64.023 - 再加 time-adaptive gating:
CD 13.843,F1 64.297
这个趋势说明,三个模块各自发挥作用,并逐步把“局部编辑”和“整体保持”同时往更好的方向推。
为什么这篇工作重要¶
3DEditVerse 的意义不止于一个更好的编辑模型,而在于它代表了一个方向性的转变:
-
数据驱动 > Tuning-free tricks:大规模高质量编辑配对数据是突破性能瓶颈的关键。116K 级别的数据规模,加上多模型协作的自动化构建流水线,为后续工作提供了可复制的范式。
-
无需掩码的端到端编辑:让模型自己学习"哪里该编辑",而不是依赖用户手动提供精确掩码。这既降低了使用门槛,又避免了掩码质量对结果的影响。
-
多阶段特征的互补设计:从同一个去噪过程的不同时步提取互补信息(保留 vs 编辑),是一个简洁而有效的思路。
从 mesh editing landscape 的发展来看,3DEditVerse 属于"第三代:在原生 3D latent 上直接编辑"的代表之一,进一步验证了 TRELLIS 骨干 + 专用编辑模块这条路线的可行性。
局限性小结¶
3DEditVerse 提交至 ICLR 2026 后,获得了 [2, 6, 6, 6] 的评分。Reviewer MB98 在讨论阶段将分数从 4 提升至 6,另外两位审稿人也明确表示 Rebuttal 完全解决了他们的顾虑。然而,评分 2 的 Reviewer dgbA 拒绝参与讨论,Area Chair 最终以"基线对比公平性问题未解决"为由决定 Reject。
1. 基线对比的公平性争议(致命伤)¶
这是本文被拒的核心死因。审稿人 dgbA 提出了以下质疑:
- 排除了基线方法的优势子集:在 Pose-driven 测试中,论文直接剔除了需要 Mask 的 VoxHammer。理由是"全身动态变形无法定义静态 Mask"——但审稿人认为这是在操纵实验环境。
- Radius Inflation 测试被视为"设局":论文通过逐步放大 VoxHammer 的 Mask 半径(+9%、+18%、+27%)来展示其性能退化,审稿人认为这是人为制造不利条件。
- 作者的辩解:即使给 VoxHammer 完美的 Ground Truth Mask(0% inflation),3DEditFormer 仍然在 7 项指标中的 6 项上胜出。但该审稿人始终不参与讨论、不更新评分。
教训:实验对比中绝不能让审稿人产生"操纵对比环境"的印象,哪怕实际意图只是验证鲁棒性。
2. 数据管线的错误累积风险¶
- 外观编辑管线极为冗长:
DeepSeek → Flux → Qwen-VL → Trellis → SAM2逐级依赖,每一环的失真都会累积。最终保留率仅 47.8%(初始 91,700 条 → 最终 43,874 条)。 - 模型偏差的疑虑:管线中的大模型可能在评估时再次出现(例如 DINOv2 同时用于数据过滤和评估指标),引发公平性问题。
- 几何编辑的泛化性受限:Pose-driven 数据集主要由人形角色动画组成(108 个角色 × 500 个姿态),审稿人质疑其对非人形物体、铰接物体的泛化能力。
3. 论文自身承认的局限¶
- Latent-space 编辑在高分辨率资产上仍可能损失一部分精细几何。
- 模型上限受限于底层 TRELLIS 表征能力,目前无法直接迁移至 VecSet 架构(如 Hunyuan3D 2.1),因为 VecSet 缺乏空间可寻址性,不支持区域级别的 Repaint。
- 虽然模型不需要 3D Mask,但数据构建管线仍然很重,离轻量交互式编辑工具还有距离。
4. 架构设计的被认可之处(正面参考)¶
值得注意的是,尽管论文被拒,但其架构设计本身获得了审稿人的广泛认可:
- Time-Adaptive Gating 被评价为"reasonable and clearly implemented",消融实验证明它在 Texture-Only / Geometry-Only / Mixed 三种编辑类型上均稳定提升。
- 双路引导注意力的解耦设计(保留信号 vs 变化信号)被认为是"novel"且"addresses an important failure mode"。
- 推理速度 19.8s (L40s GPU) 与 EditP23 (9.8s) 在同一量级,远快于 VoxHammer (69.8s)。
这说明:好的架构设计不能拯救有争议的实验设置——评估的公平性与严谨性同样(甚至更加)重要。