VIGA¶
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
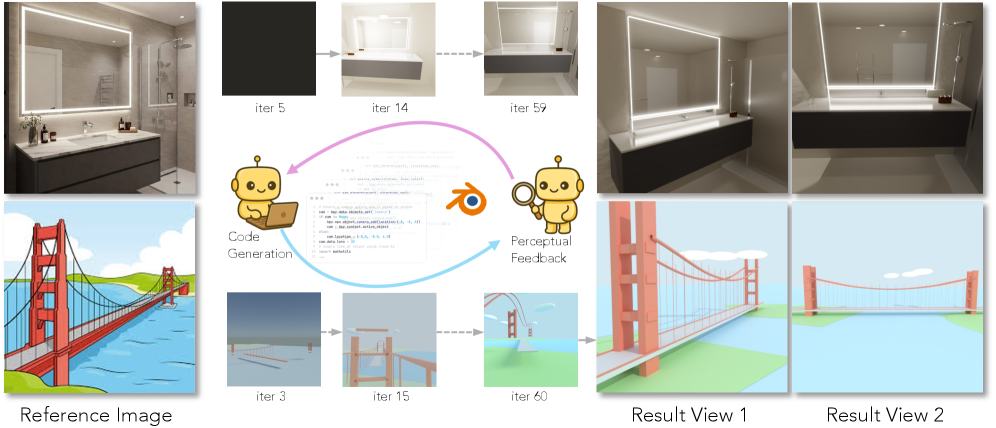
VIGA 把逆向图形问题改写成一个代理式反馈循环:模型先写 Blender 场景脚本,再执行、渲染、检查当前结果,并根据视觉差异继续修改代码。它更关心的是,模型如何在执行反馈中逐步把程序改对,而非一次就写对。
核心问题¶
论文首先指出,强 VLM 仍然很难一次性从图像写出正确的 3D 场景程序。症结不只在语言能力,还包括:
- 相机位姿难以精确推断
- 物体布局、尺寸和朝向难以一次定准
- 材质、光照、遮挡等误差往往需要多轮检查才会暴露
因此,VIGA 的问题设定是:
能否把单图到 3D/4D 场景重建写成
write -> run -> render -> compare -> revise的多轮反馈循环?
整体框架¶
VIGA 由两个角色交替工作:
- Generator:根据当前记忆写或修改场景程序
- Verifier:从多个视角检查执行结果,指出和目标图像的主要差异
text
参考图像
-> Generator 写代码
-> Blender 执行并渲染
-> Verifier 检查当前结果
-> 文本化差异与修改建议
-> 下一轮代码更新
论文把这件事称为 interleaved multimodal reasoning,因为模型不仅在文本里思考,还会借助图形引擎不断观察和修正。
1. Skill Library¶
VIGA 的关键在于围绕图形引擎组织起来的一组工具。
Generation 侧工具¶
make_planexecute_codeget_scene_infoget_better_assetsend_process
Verification 侧工具¶
initialize_viewpointset_camerainvestigateset_keyframeset_visibilityget_scene_info
这些工具的作用是把“检查错误”从模糊的语言判断,变成可执行的观察动作。例如:
- 切换相机
- 放大局部
- 聚焦某个物体
- 检查 4D 场景的关键帧
这样 Verifier 给出的反馈会从“看起来不太像”推进到更接近可执行的编辑建议。
2. Evolving Context Memory¶
多轮代码修正很容易遇到上下文爆炸问题。VIGA 的解决方式是维护一个不断更新的记忆窗口,里面保留:
- 最近的计划
- 代码差分
- 渲染历史
- Verifier 的文字反馈
论文的一个判断很实用:旧轮次并不需要全部保留,因为最新程序本身已经吸收了很多历史修改结果。于是系统只保留最近若干轮,避免上下文太长导致推理退化。
这使 VIGA 更像“带执行记忆的代码代理”,而不是简单的链式提示。
3. 为什么它和普通 3D code generation 不同¶
如果把 MeshCoder 一类方法看成“shape -> code”的一次映射,那么 VIGA 更像“image -> code -> render -> code revision”的迭代系统。
二者的差别在于:
MeshCoder更强调程序表示本身VIGA更强调程序能否在反馈循环中被逐步修正
因此,VIGA 代表了一条 agent 化的 inverse graphics 路线:程序更像中间工作状态,而不是终点。
4. 适用任务范围¶
论文强调这个框架并不限于静态单场景重建,而是覆盖:
- 3D scene reconstruction
- multi-step scene editing
- 4D physical interaction
- 2D document editing
就 3D 方向而言,它最值得注意的地方是:没有额外几何监督模块,也不依赖任务专用微调,而是只靠基础 VLM 在执行反馈中不断修正程序。
5. 实验结果¶
论文在多个基准上报告了明显提升:
- BlenderGym:相对 one-shot baseline 平均提升约
35.32% - BlenderBench:平均提升约
124.70%
其中 BlenderBench 专门设计了更难的三类任务:
- camera adjustment
- multi-step editing
- compositional editing
这些任务本质上都在考察一件事:
模型是否能把视觉差异转成下一轮代码修改,而不是只写出第一版程序。
论文还指出,随着任务变长,结构化记忆的重要性会迅速上升。没有状态跟踪时,复杂组合编辑很容易崩掉。
6. 价值与局限¶
价值¶
- 把 inverse graphics 明确写成代码代理问题
- 说明多视角主动检查对场景脚本修正很关键
- 不依赖额外微调,能直接作为基础模型能力测试框架
局限¶
- 结果仍受基础 VLM 的视觉定位能力限制
- 工具检查粒度有限时,细小几何误差仍可能漏掉
- 多轮过程对上下文和预算要求较高
从研究定位看,VIGA 更像一个把程序生成、执行反馈和多模态推理结合起来的外层系统,不属于新的几何表示方法。
一句话总结¶
VIGA 的意义,在于把单图到 3D/4D 场景的逆向图形问题改写成一个可执行反馈循环:模型不必一开始就把脚本写对,而是可以在渲染反馈中持续修正程序。