Instructive3D¶
Instructive3D: Editing Large Reconstruction Models with Text Instructions
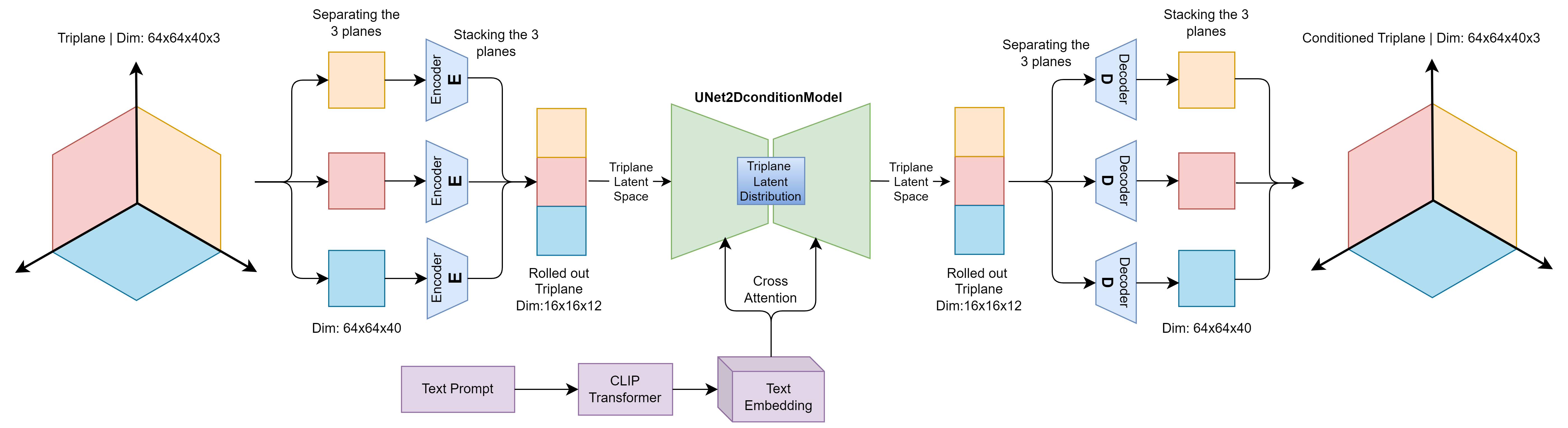
Instructive3D 的目标很明确:把 LRM 从“只能重建 3D”扩展成“还能根据文本做细粒度编辑”。它的方法是在 triplane latent 上加一个文本条件 diffusion adapter,不需要重新训练完整 3D 模型。
核心问题¶
LRM 一类方法很适合从单图生成 3D,但缺少细粒度控制:
- 想改颜色、材质、纹理细节不方便
- 想通过一句话给对象加某种图案或表面属性也不直接
Instructive3D 的问题意识是:
能不能不给 3D 编辑模型准备昂贵的成对 3D 编辑数据,而只在 latent 空间里用文本引导做编辑。
方法框架¶
1. Triplane latent editing¶
- 先用预训练 LRM 得到 triplane features
- 再在 triplane latent space 上做 diffusion-based editing
- 文本 prompt 作为编辑条件输入
2. Adapter 而不是重训 backbone¶
- 预训练 LRM 负责提取和解码 triplane
- 新训练的主要是一个 triplane diffusion adapter
- 因此训练成本比从头训练 LRM 小很多
3. 数据构建¶
- 用 InstructPix2Pix 等 2D 基础模型先生成编辑后的图像
- 再借助预训练 LRM 提取对应 triplane latent 作为监督
- 避免直接准备大规模 3D 编辑对
关键实验结论¶
论文将 Instructive3D 与 Text2Mesh、Paint3D、TEXTure 做对比,结果显示它在大多数指标上更好:
LPIPS = 0.0278SSIM = 0.951FID = 114.91KID = 0.0457PSNR = 40.47
对比里:
Text2Mesh:LPIPS 0.1986,PSNR 37.25Paint3D:LPIPS 0.1061,PSNR 39.48TEXTure:LPIPS 0.0995,PSNR 39.54
这说明在它的实验设置下,直接在 triplane latent 上做文本编辑,比这些较早的纹理/风格方法更稳。
VAE 消融¶
论文还比较了:
- 单个 3D VAE
- 三个分离的 2D VAE(对应三张 triplane)
结果是分离的 2D VAE 更好,训练损失和 MSE 都更低。这说明 triplane 的三个平面分开编码是更自然的设计。
为什么它重要¶
Instructive3D 的意义在于,它把“文本编辑 LRM”这件事变成了一个较低成本的适配问题:
- backbone 不必重训
- 数据不必直接收集 3D 编辑对
- 编辑信号可以直接来自语言
这让 LRM 从纯 reconstruction model 朝可控生成系统迈了一步。
局限¶
- 仍然依赖预训练 LRM 生成的 triplane 质量,底层表示不准时编辑上限也会受影响
- 主要是材质、纹理、表面层面的细粒度编辑,不强调复杂结构重构
- 论文本身也指出没有真实 triplane ground truth,监督信号仍有间接性
一句话总结¶
Instructive3D 的主要贡献,是在 LRM 的 triplane latent 上加入文本条件 diffusion adapter,让单图重建模型具备了更细粒度的文本驱动 3D 编辑能力。
评论
评论功能当前未启用。当前站点不依赖 GitHub 评论服务;如果后续需要评论,建议接入自托管评论后端。